

We’re Building Agents on a Foundation Most Engineers Have Never Heard Of
Control and data planes, static stability, and what an agentic layer actually does to the separation.

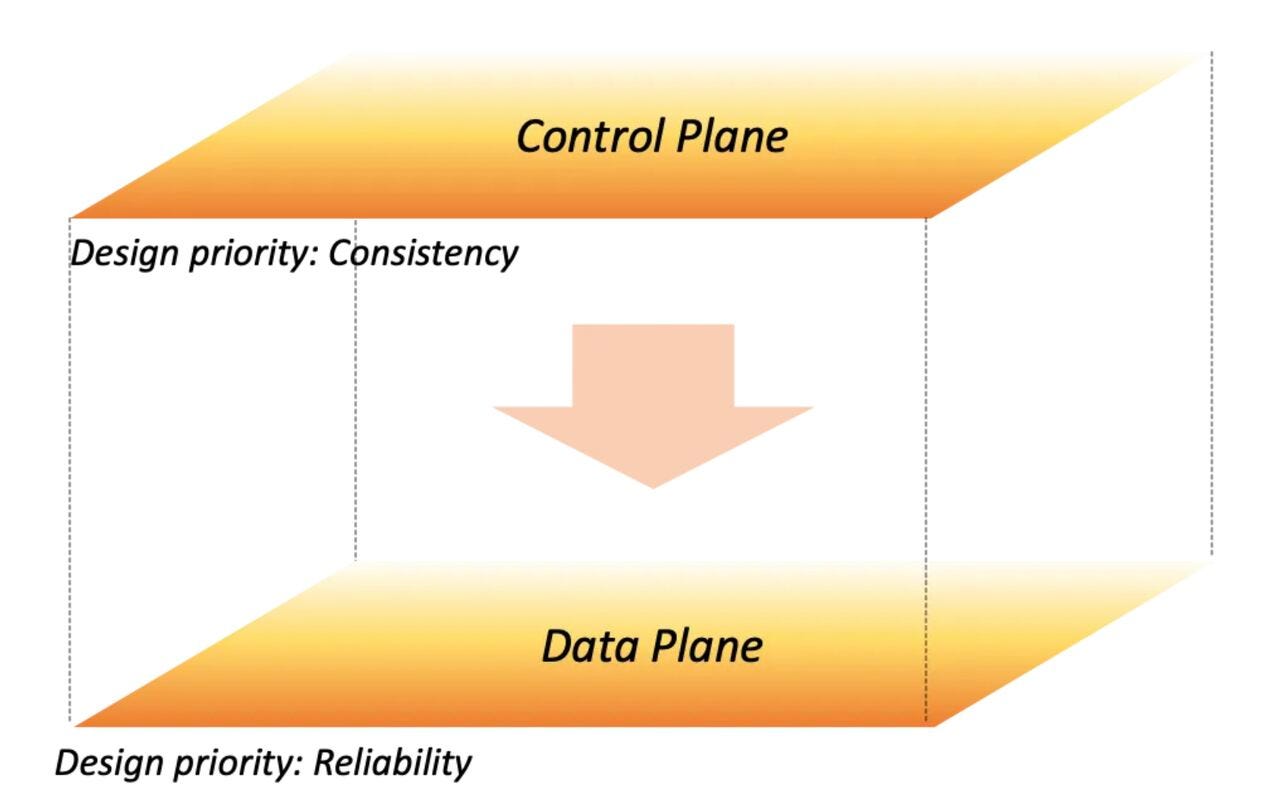
The control plane / data plane distinction is one of the most useful ideas in system design, and one that most engineers have never heard of. That gap didn’t matter very much for a long time, but it matters now, because the industry is busy adding an agentic layer on top of production systems, and that layer sits right on the part of the architecture the gap tends to hide.
Let’s first look at the idea itself, because you can’t reason about what an agent does to it until you can name it.
Control & data planes
The terms come from networking, from routers specifically. The control plane decides how traffic should be routed, and the data plane actually moves the packets. In distributed software systems the same split generalises nicely: you use the control plane to manage your resources, and you use the data plane to use them. Put another way, the data plane sits on the request path, the part your users actually touch, while the control plane sits beside it and helps it do its work.
The analogy I keep coming back to is car manufacturing. The factory is the control plane, in that it designs the car, configures it, sources the parts, and produces it. The car is the data plane. Once it has been built it drives, and it keeps driving even when the factory is closed for the weekend or stuck in some supply-chain mess, because the car already carries everything it needs to do its job. It doesn’t have to phone the factory before every turn of the wheel.
We separate these two roles mainly for reliability, so that an outage in one plane does not take down the other. The control plane is where most of the complexity lives, with more dependencies, more elaborate logic, more code paths that only run once in a while, and a heavier resource footprint. The data plane is kept deliberately simpler, and that simplicity is really the whole point, because it makes the data plane statistically less likely to fail than the control plane.
Out of that comes a discipline that sounds obvious the moment you say it and yet gets violated all the time: don’t depend on the control plane to recover from an outage. During an incident, the control plane is the part most likely to already be impaired, precisely because it is the more fragile of the two, so if your recovery path runs through it you have built your recovery on the least reliable thing you own.
This is where static stability comes in. A statically stable system keeps its steady state through a disturbance without having to do any work to get there. Imagine a service running across three zones behind a load balancer, with enough capacity pre-provisioned in each zone that any two can absorb the full traffic if the third goes down. When a zone becomes impaired, the load balancer routes around it and the remaining zones simply take the extra load, with no instance to launch, no scaling decision to make, and no control-plane call on the critical path. The data plane keeps working because it already has what it needs, and it would keep working even if the entire control plane were dead. You pay for this with over-provisioned capacity, which is the permanent tension between resilience and efficiency, and what you get in return is the ability to keep serving customers while the clever parts of the system are down.
Now put an agent on top
You could argue that an agent doesn’t change the picture at all. An agent that acts on a system is a control-plane client, just like a human typing `kubectl` is a control-plane client. Swap one for the other and the architecture is the same, the separation in the underlying system stays just as valid as it was.
But a few things do change in practice.
The first change is that we quietly lose a safeguard nobody ever bothered to write down, which is human slowness. Control-plane access has always been dangerous, and the reason it stayed survivable is that humans are slow: we run one risky command and watch what happens before reaching for the next, we hesitate in front of the irreversible ones, and eventually we get tired and go home. That pacing was doing real safety work, and because nobody had named it, it gets removed along with the toil the moment the task is automated. Nothing actually forces an agent to be fast, since you can pace it, throttle it, or make it stop and ask, but the whole momentum of the field runs the other way, toward more and faster, so in practice the brake is being taken off by choice rather than by necessity.
The second change is mechanical, and it’s the one that worries me most. Metastable failures occur when a trigger event puts a system into a bad state that persists even after the trigger is removed. The system keeps failing not because of the original problem, but because of a sustaining feedback loop that prevents recovery: retries amplifying load, queues growing, memory pressure increasing latency which increases in-flight requests which increases memory pressure. The trigger is long gone and the system is still down. The original research comes from Bronson et al., and Marc Brooker has written about it in the context of distributed systems design.
A fast, reactive agent in the operational loop can become exactly that sustaining loop. An agent optimising for something local, such as clearing an alert, and acting on the control plane faster than the system can settle, is a very efficient way to turn a passing problem into a stable bad state. A human in that position is usually slow enough to potentially notice the loop forming and step back, whereas an agent generally isn’t.
There is a third problem, and it lives inside the agent platform itself. The current fashion is to put a governance layer that handles identity, policy, approvals, and audit directly in line with every action the agent takes. In the operator pattern, where the agent sits to the side managing a system, this means every agent action has to call out to the governance layer before it can proceed. In the increasingly common inline pattern, where the agent IS the user-facing layer (think AI customer support or Salesforce Agentforce), user requests flow through the agent and therefore through the governance layer too. In that second case, what was meant to be control-plane work has quietly become a data-plane dependency: if the governance layer is down, user requests stop, not just agent actions. Either way, you end up with a component that has the complexity and fragility of a control plane but the availability requirements of a data plane, and that combination is exactly what the separation exists to avoid.
Static stability, and where the agent fits
Go back to the three-zone example. The system absorbs the loss of a zone because the capacity is already there. You could also add automation that watches health metrics across zones and shifts traffic away from one that starts looking unhealthy, getting out of the way of trouble before it spreads. That automation is useful, but it is a separate job from the static stability underneath it. The zones absorb the load whether or not the automation runs, because the capacity was pre-provisioned. The floor holds either way, and the automation is an optimisation standing on top of it rather than a part of it.
That is exactly the right model for an agent. The agent is the automation, not the floor. It can watch, decide, and act to make things better, but it cannot be the thing the system depends on to survive. If you build the system so that it stays in its steady state whether the agent does the right thing, the wrong thing, or nothing at all, then the agent being wrong is a matter of degraded optimisation rather than an outage.
What respecting the separation looks like
Most of the shape of a well-behaved agentic system falls out of that one requirement.
The agent should operate the system as a control-plane client, off to the side of the user’s data path, so that users keep being served even when the agent is down, slow, or simply wrong.
Whatever the agent would otherwise have to ask for, you want to put in place ahead of time. People usually frame this narrowly, as pre-issuing scoped, short-lived credentials so that authorisation doesn’t need a live call, but the idea is more general than auth. Any control-plane operation the agent leans on, whether it’s a policy lookup, a configuration read, or a capacity decision, can be staged into the path in advance, so that the agent acts on what’s already there instead of taking a live dependency that will fail at exactly the wrong moment. It’s the same move as pre-provisioning capacity, applied to everything the agent touches.
Reversibility is a good way to decide how an action should be routed. Reversible and read-only actions can take the fast local path and are allowed to fail open, while irreversible, destructive, or privilege-escalating actions should go through the control plane and fail closed, so that dropping the production database becomes impossible the moment the approval system is unavailable, without a routine read dying alongside it.
The agent also needs an explicit budget for how much it can do. Humans came rate-limited by biology, but an agent has to have that limit written down, something along the lines of the token-bucket approach Marc Brooker describes for retries, because an agent without a budget is just an unbounded client, and unbounded clients are how ordinary overload turns into collapse.
Its authority should also be scoped for blast radius, so that a cell or a shard is the most that any single wrong action can affect, rather than the whole estate.
The question underneath
It’s worth noticing what that list actually is. Pacing, hesitation before the irreversible, a fixed budget, a sense of when the right move is to do nothing: these are the human traits that made unrestricted control-plane access survivable in the first place. The safety was never really coming from the human’s speed or scale; it was coming from the human’s brakes.
Which leaves us with a slightly uncomfortable tension. To make an autonomous agent safe on the control plane, you find yourself re-encoding the very traits you took the human out to get away from. The hardest thing to teach an agent may well turn out to be restraint, and if you teach it that well, you have more or less rebuilt the operator you were trying to automate, at which point it’s fair to ask what the agent was for in the first place. The most likely answer is that the agent belongs where speed and scale are the point and the brakes are cheap, which is the reversible, read-heavy, high-volume work, and that the irreversible control-plane path is precisely where you should be slowest to send it.
The foundation already tells you where the agent belongs and where it doesn’t. The trouble is that you can’t apply a separation you’ve never heard of, and most of the people now wiring agents into production systems have never heard of it.
//Adrian