

The Interpretation Layer
Why detection isn’t enough, and what the recent Lovable incident tells us about the often most neglected part of your organization.


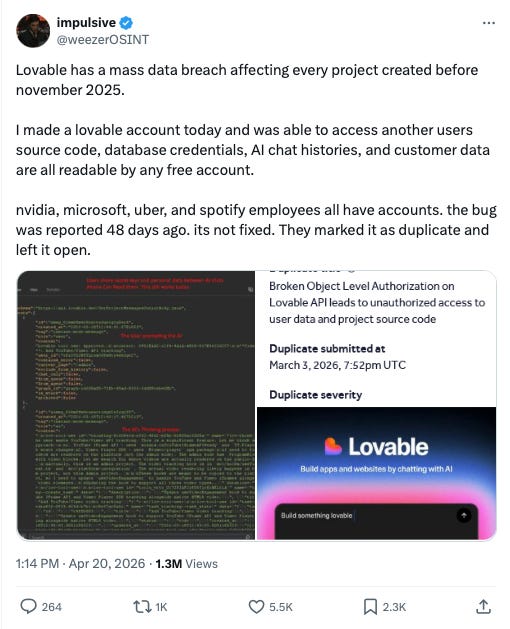
On April 20, 2026, a security researcher named @weezerOSINT publicly disclosed that chat histories and source code from public projects on Lovable, the AI (vibe)coding platform, could be accessed by any authenticated user. After some back and forth, in what became a great lesson in how not to respond to vulnerability reports, Lovable shipped a fix. It published a detailed postmortem two days later. Most of the coverage has focused on the Public Relations handling (or lack thereof) and security failure itself: a backend regression reintroduced access that had been deliberately removed over the course of 2025, exposing user data for roughly ten weeks.
That’s the story most people are telling. I want to tell a different one.
Buried in Lovable’s postmortem is a detail that changes what the incident is about. Researchers caught the regression. They filed reports through the proper channel, HackerOne, starting February 22. The first report landed within weeks of the regression shipping. The detection system worked exactly as designed.
And then, for two months, every report was closed as “expected behavior.”
The signal was not missed. The signal was received, interpreted, and dismissed. Not by malice, not by incompetence, but by a triage layer operating on documentation that no longer matched the product it was describing. The detection system worked. The interpretation layer failed.
This is the failure mode nobody writes about, and it lives in almost every organization I’ve worked with.
Chinese whispers at organizational scale

You have probably played Chinese whispers, often called telephone. A group of kids sits in a line. The first whispers a message into the second’s ear. The second passes it to the third. By the time it reaches the end, “purple umbrella in the rain” has become “people wrestling trains,” and everyone laughs because the punchline is always the mangled message at the end.
What the game illustrates is more useful than the laugh.
Notice what does not fail in Chinese whispers. The signal is intact at the source. Every person in the chain is acting in good faith. Every person is passing along what they heard, faithfully, with some confidence. No individual link is broken. The failure is distributed across the chain itself, in the coupling between links, and crucially, nobody in the middle knows how the message has drifted. Each person only hears one version and passes it on. They cannot check their interpretation against the original because they do not have access to the original. They only have what the previous link handed them.
This is exactly the shape of the Lovable failure, and of most interpretation layer failures I have seen. The researchers filed accurate reports. The triagers compared those reports to the documentation they had been given. The documentation was an artifact from an earlier version of the product. Each link in the chain acted correctly against its own inputs. The whole chain produced the wrong output, with complete confidence, for ten weeks.
The game is a children’s game because the stakes are a laugh. At organizational scale, with real systems and real users, the stakes are incidents, lawsuits, and eroded trust. The mechanism is identical.
The three-layer model
Think about how signals flow through your organization. There are at least three distinct layers involved in turning an external or internal event into an organizational response.
Detection is the layer that captures the signal. Monitoring, alerting, bug bounties, customer support tickets, audit logs, researcher reports. Most organizations invest heavily here, because detection failures are visible and embarrassing. When an outage hits and nobody saw it coming, the question “why didn’t we detect this?” is the first one asked.
Response is the layer that acts on the signal. Runbooks, on-call rotations, incident commanders, remediation workflows. This layer gets moderate investment, usually in the form of process and tooling.
Between them sits interpretation. The layer that decides what the signal means. Is this alert real or noise? Is this report a vulnerability or expected behavior? Is this customer complaint a bug or a misunderstanding? Interpretation almost always happens implicitly, inside the heads of whoever is looking at the signal, supported by whatever documentation was accurate the last time someone updated it.
The interpretation layer is where Lovable’s incident lived for ten weeks. And it’s the layer most organizations treat as if it doesn’t exist.
Why interpretation drifts
Three mechanisms push the interpretation layer out of sync with reality, and they operate continuously in every system I have ever seen.
The first is that interpretation context is static while the system it describes is dynamic. Documentation is written once, updated occasionally, and consulted continuously. Products change every deploy. The half-life of accuracy in any piece of interpretive context is short, and almost nobody is measuring it. The moment you ship a change that affects how an external signal should be interpreted, you have created a drift window. The question is only how long the window stays open.
The second is that interpretation is often outsourced, literally or functionally. Triage partners like HackerOne, support vendors, junior staff, automated classifiers, LLM-based first-line responders. They operate on context handed to them, with no independent way to verify that context against current reality. They also have no incentive to question it. Questioning the context means slower ticket closure, more escalations, and the appearance of not doing your job. The incentive structure rewards confident application of whatever context you were given.
The third is the most insidious. Successful interpretation looks identical to correct interpretation from the outside. A closed ticket is a closed ticket. The dashboard shows healthy throughput. The SLA metrics look fine. You only discover the difference between “interpreted correctly” and “interpreted consistently with outdated context” when the suppressed signal becomes undeniable, usually through public disclosure, a major outage, or a regulator knocking on the door. By which point you have months of accumulated evidence that your process was working, which makes the eventual failure both more surprising and more damaging.
The work-as-imagined gap
If you have read any of my previous work, you know I spend a lot of time on the gap between work-as-imagined and work-as-done. The Lovable incident is a near-perfect illustration.
The product team imagined the disclosure process as: researcher files report, we investigate, we fix. Clean loop, clear ownership, visible outcomes.
The actual work-as-done was: researcher files report, triager compares the reported behavior against Lovable-provided documentation, documentation describes the behavior as intended, ticket closes as “not a vulnerability.” Also a clean loop, with clear ownership and visible outcomes. The two loops produce identical metrics. They diverge only in what they do with actual vulnerabilities.
Nobody in the product loop could see the triage loop. Nobody in the triage loop could see that the product had changed. The organization had built a pipeline where each stage was functioning correctly by its own lights, and the failure existed only in the coupling between stages, which nobody owned.
This is where it helps to name the deeper pattern. Failure in complex systems is overwhelmingly a property of emergence, not of components. Each component can be tested, verified, documented, and owned. The interactions between components cannot be fully tested in advance, because the interaction space is combinatorial and the only place the real combinations happen is production. Woods, Hollnagel, and Cook have been writing about this for decades. Complex systems fail at the joints, not at the parts.
Interpretation layer failures are a particularly clean example of this principle. The product was working. The triage process was working. The researchers were doing their job. The failure lived entirely in the coupling, in the flow of interpretive context from product to triage, and coupling is structurally harder to own than components. Components have teams. Interfaces between components tend to be orphaned by default, because assigning ownership of a coupling requires someone to actively notice that the coupling exists and matters. In fast-moving organizations, that noticing usually happens after the incident, not before.
This is how interpretation layer failures almost always look. Not dramatic. Not obvious. A slowly widening gap between what the system is doing and what the interpreters think it is doing, invisible until the gap produces an incident big enough to reach the public.
Read the remediation
Here is where Lovable’s postmortem gets interesting, because it contains both the right diagnosis and the wrong remediation, and the ordering tells you something.
The postmortem announces two categories of fix. Training: “extensive product training to all HackerOne triagers,” “retraining our HackerOne triage team on Lovable’s current permission model.” And infrastructure: “restructuring our escalation workflow to ensure that any product change affecting user data access automatically triggers an update to our triage documentation.”
Training appears first in the communication. Infrastructure appears as a subordinate clause inside a longer paragraph.
This is backwards, and it matters. Not because training is wrong. Training matters. The humans in the interpretation layer are the interpretation layer. You cannot automate them out, and you should not want to. What matters is what training can and cannot carry on its own.
Training fixes knowledge gaps in people. It does not fix freshness gaps in artifacts. If you retrain the triage team today on the current permission model, you have solved the problem for exactly as long as the permission model stays current. At any platform shipping changes continuously, that window is measured in weeks. Then you are back in the same state, except now you have a false sense of having addressed it, because you did the visible thing.
The automated trigger, the coupling between product changes and triage documentation updates, is the fix that holds across time. It does not decay the moment you stop paying attention. It makes the interpretation layer self-updating, or at least self-alerting when it falls behind. It gives the trained humans fresh context to work with, instead of making them rely on memory of context that is aging out. Training and infrastructure are not substitutes for each other. They are complements, and most organizations invest in the first while neglecting the second.
Sidney Dekker has written extensively about the temptation to locate systemic failures at the human layer. It is the cheapest intervention to announce. It shows care for the people involved. It produces a deliverable. The problem is not that it is wrong, but that it is incomplete. Training humans to interpret stale context correctly does not prevent the context from going stale again next quarter. The system that created the conditions for drift keeps producing them, and humans alone cannot hold back drift they have no way to see.
This gives you a small diagnostic you can apply to any incident postmortem, your own or someone else’s. Look at the remediation list. Count the training items versus the infrastructure items. The ratio tells you where the organization believes the failure lived. If training leads, the organization still thinks this was a people problem. If infrastructure leads, they have absorbed that it was a systems problem.
Lovable is doing both, which is better than most. But the prominence of training in the communication is a tell. The organization is not yet convinced that the interpretation layer is infrastructure. It still thinks of triagers as people who need better preparation, rather than as sensors that need fresher input signals.
What to do about it
If you accept the premise that interpretation is infrastructure, a few concrete patterns follow. All of them share a common move: making the coupling visible, ownable, and instrumented. Breaking the Chinese whispers structure by giving the chain ways to check itself against the original.
Treat interpretation context as a deployment artifact. If product changes ship through a pipeline, the context that downstream interpreters need to correctly handle those changes ships through the same pipeline. Not as a Notion doc someone might update. As a versioned artifact with ownership, review, and a release cadence tied to the underlying system. Lovable’s automated-trigger fix is a version of this. It can be done more rigorously.
Instrument the interpretation layer itself. What is the rate of external reports being closed as “expected behavior” or “not reproducible” or “working as intended”? Is that rate changing over time? Are specific reporters being repeatedly dismissed? These are leading indicators of interpretation drift, and almost nobody tracks them. You do not need fancy tooling. A monthly review of closure reasons, segmented by category, would catch most drift before it becomes an incident.
Build a feedback path from response back to interpretation. When a real incident happens, the first question in the postmortem should be: did our interpretation layer suppress earlier signal, and if so, why was the context wrong? Lovable is doing this retrospectively for one incident. The resilient version does it as standing practice, for every significant incident, every time.
Assume the interpretation layer is drifting right now. You do not know in which direction. Periodic red-team exercises where someone files a known-real issue through the normal channel and watches what happens. Synthetic reports, seeded bugs, planted scenarios. Cheap, high-signal, almost never done. If you cannot bring yourself to do this, at minimum review a random sample of closed tickets every quarter and ask whether the closure decisions still hold up against the current state of the product.
The adverse incentive
One last thing worth naming. There is an incentive problem in how incident communications get read.
Training remediations are legible. They sound decisive. They show empathy for the people who were let down. They produce a clear before and after story. The organization that announces comprehensive retraining looks responsive.
Infrastructure remediations are invisible when they work. An automated documentation trigger that quietly keeps triage context fresh for the next five years produces no headlines. It generates no narrative. It looks like nothing happened, because nothing did, which was the goal.
The infrastructure half is invisible when it works. Training initiatives announce themselves. Automated documentation triggers do not. This is the prevention paradox applied to incident response, and it creates pressure to lead with training in communications even when the organization knows better. Training is visible. Infrastructure is not. The combination is what produces resilience, but only one half of it tells a good story.
Naming this pressure is the first step in resisting it. If you are writing a postmortem, lead with the coupling fix. If you are reading one, discount the training and look for the infrastructure underneath. The training tells you what the organization wants you to see. The infrastructure tells you what will change.
Closing
Every mature organization has invested heavily in detection, because detection failures are visible, embarrassing, and easy to blame on missing tools. Response has received moderate investment, because response failures produce dramatic incidents that demand process improvement.
The interpretation layer sits between them, quietly translating signals into action, drifting continuously, invisible until it produces the kind of failure Lovable had. Most of the time, nobody owns it and nobody measures it. When it fails, organizations reach for the remedy they can see, training, because training is legible and infrastructure is not. Training alone is not enough. It has never been enough. The next frontier of resilience work is not better detection or faster response, it is treating the layer between them as infrastructure that supports the humans doing the interpretation, with the ownership, instrumentation, and deployment discipline that implies.
The detection system worked. The interpretation layer failed. That sentence will fit almost every major incident you read about this year. The question for you to think about is whether your organization is building the muscle to notice when it applies to you, before the researcher writes the blog post.
//Adrian