

No Change Left Behind
Bringing discipline to manual changes


I think we can all agree that, ideally, most production changes should go through a pipeline. Most organisations are moving that way. But the business does not pause while the migration happens. Certificates expire, databases need manual intervention, one-off changes come up. These still happen, and they still need discipline. What they usually get instead is a change ticket nobody reads and an approval stamp from someone who was not building shared understanding of what was about to happen.
And when one of these changes goes wrong, the investigation finds what it always finds: the operator skipped a step, or missed a dependency, or forgot to check whether the customer was in the middle of something. The report calls it human error, the process gets a new approval gate, and the next operator routes around the gate the same way the last one did. The gate addresses the symptom of a procedural failure without touching the cognitive problem underneath it.
The cognitive problem is that planning, executing, and verifying a production change are three fundamentally different modes of thinking, and most tools and processes mix them together. The operator is filling in a change ticket while also thinking about the commands they will run, while also trying to remember what they are supposed to check afterwards. Planning bleeds into execution. Execution bleeds into verification. The operator ends up in a mode where they are simultaneously anticipating, doing, and confirming, and the quality of all three suffers because the human brain is not built to hold three cognitive frames at once.
Mica Endsley’s situation awareness model helps explain why. Situation awareness, in her framing, has three interdependent levels: perception (what is happening), comprehension (what it means), and projection (what happens next). Each phase of a change leans on a different one. Pre-flight leans on projection — what could go wrong, what the customer is in the middle of, what the blast radius looks like if it fails — though it also demands perception and comprehension of the current state, the dependencies, the constraints. Execution leans on perception and comprehension — reading the output, comparing it to what you expected, deciding whether to continue. Verification re-checks comprehension from a different vantage point: not “did my command work” but “can the customer do what they were doing before.” These are different cognitive postures, and collapsing them into a single form with a single approval gate is how you get an operator who checks a box without thinking about what the box means.
Aviation figured this out decades ago. Pilots do not run pre-flight checks, fly the aircraft, and verify the landing in one continuous stream. Each phase has its own checklist, its own mental posture, its own verification. The transitions between phases are explicit. Atul Gawande made the case in *The Checklist Manifesto* that the value of a checklist is not in telling experts what to do — they already know — but in forcing the pause that prevents omission under pressure. The surgical checklist does not make surgeons more skilled. It makes the skill they already have more reliably applied.
What forcing functions look like in practice
A cognitive forcing function is a design element that makes you think about something you would otherwise skip. Not because you are careless, but because the cognitive load of the situation naturally pushes certain considerations out of working memory.
The pre-flight questions in a change process should work this way. The question “if this change fails mid-way, what is the customer in the middle of doing?” is a forcing function. The operator knows the customer exists. They may even know the customer’s workflow. But under the pressure of getting the change done, they are not spontaneously going to simulate the customer’s state at the moment of failure. The question forces that simulation. It does not decide anything. It just makes the operator think about something that would otherwise remain unconsidered.
The sequence of questions matters as much as the questions themselves. What you are doing, then who it affects, then what happens if it goes wrong, then whether the timing is right for the customer or just convenient for the operator. Each question builds the part of the mental model the next one depends on: you cannot reason well about failure modes before you have a clear picture of what the change touches and who relies on it. Scramble the order and the forcing function weakens, because the operator is asked to project consequences before they have perceived and understood the situation those consequences play out in.
During execution, the forcing function is different. It is the read-do pattern: read the step, do it, record what you observed. Not “done” but what you actually saw. The observation forces the operator to compare reality to expectation instead of just checking a box. And the sequential unlock because you cannot move to the next step until the current one is confirmed which prevents the batching and skipping that happens under time pressure.
Hold points are the forcing function. Execution stops. A second person must verify before you can continue. The verifier sees what the operator saw, at the point in the process where it matters most. The enforcement here is not technical because the system does not prevent you from verifying your own hold point. The enforcement is the audit trail. Every completion and every verification is recorded with a name and a timestamp. If you self-verify a hold point, that fact is permanently visible to anyone who looks at the change record. The discipline comes from accountability, not from a gate.
Why this matter
All of this is more deliberate than dropping a line in a ticket, and for a while a company can get away without it. Early on, when a change breaks something, customers forgive it, because the product is giving them more value than the outage is costing them. That forgiveness may be earned, but it is also slack. It hides the fact that the way the organisation makes changes was never actually safe, just not expensive yet.
Then the company grows. The customers it sells to now are buying reliability. Some are regulated. Some have penalties in the contract. A change that takes them down stops reading as the quirk of a scrappy vendor and starts reading as a failure of the thing they paid for. The move-fast change culture that growth rewarded becomes the thing that erodes the trust the next stage depends on. What got the company here will not get it there, and the change process is one of the first places that shows.
What I built
I built two things, for two stages of the same journey. Both are open source. Both do the same job: take a manual change through three structurally separate phases — pre-flight, execution, verification — with the cognitive forcing functions I described above. Neither is a runbook tool or a CI/CD replacement. Most production changes should flow through a pipeline, and these have nothing to say about those. But some changes cannot go through a pipeline; infrastructure migrations, manual database operations, one-off platform changes, the things that still require human judgement. Those changes still happen, and they still need discipline. The difference between the two is how much you want to adopt.
The first is a Claude skill, for starting today. Change-management is a skill for Claude. Since a lot of teams already use Claude, there is nothing new to stand up. You describe a change in plain language and it walks you through it, one question at a time: the pre-flight thinking (pushing back on shallow answers and capturing your hedges honestly), building the checklists, then guiding execution step by step. It presents each command in a copy-ready block, you run it and paste back the actual output, and it records what happened, including the adaptations the plan did not anticipate. If a change becomes a live incident, it says so and hands off to incident response. It writes a markdown record into a plain git repository, so the audit trail is a byproduct of doing the work. No new platform, no migration, the lowest possible barrier to better changes.
Second is Changebook, for when you want a dedicated tool. Changebook is a purpose-built application for the same lifecycle, for once the process has settled and a team wants it enforced rather than guided. The pre-flight profile forces thinking about blast radius, rollback, customer impact, and timing before a single command runs. The execution checklist enforces sequential read-do with recorded observations and hold points. The verification checklist confirms the change worked from the customer’s perspective, not just the operator’s. Everything is audited. The full change — who proposed it, who reviewed it, what was executed step by step, what was verified — is an immutable record. Any edit after approval resets all reviews, so an approved change cannot drift from what was reviewed. Templates grow from executed changes, not from planning documents. And the markdown export means every change record can be stored in git, attached to an ITSM ticket, included in a regulatory submission, or fed into an LLM for pattern analysis.
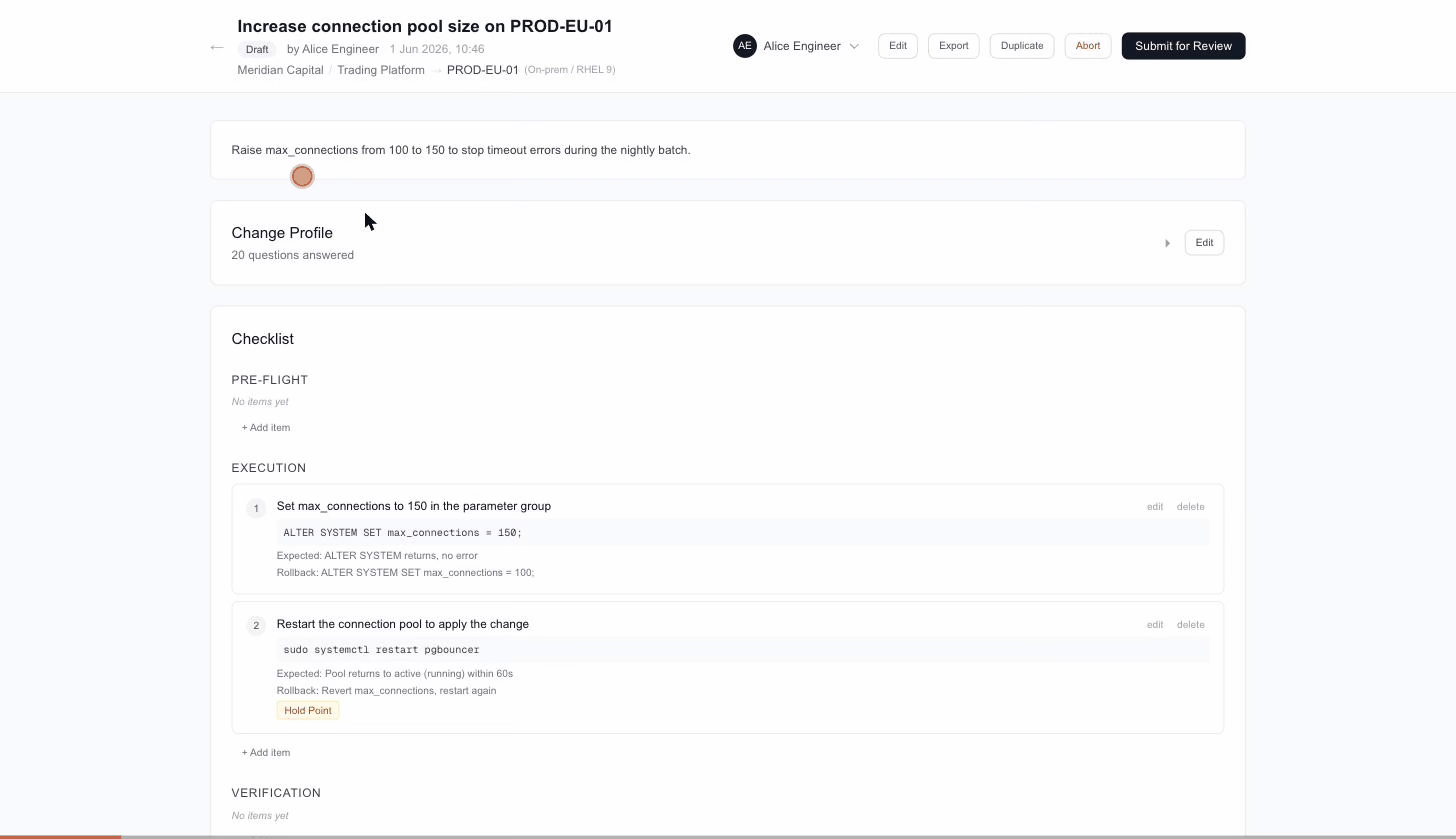
The skill and the tool produce the same shape of record, so a team can start with the skill today and move to the tool later without throwing anything away. Start light, expect it not to be perfect, and improve it as you learn what fits.
Several of my customers have needed something like this. Rather than explain the concept and guide each of them to build their own version, I built it. It saves everyone the energy, building is fun, and hopefully it helps others too. Both are early, but functional and close to feature-ready.
The reflex when changes keep causing incidents is to add more process: more approval gates, more oversight. But a form that mixes planning, execution, and verification, signed off by someone who never built shared understanding of what was about to happen, is not a procedure. It is paperwork. Both of these are my attempt to replace that paperwork with something that actually helps the operator think, and to meet a team wherever it is, whether that is “we could start this afternoon” or “we are ready for a real tool.”
What I want now is feedback from people who think and know about how operators actually work. Does the pre-flight sequence force the right thinking? Are the hold points in the right places? What is missing? If you have run real changes under pressure, I want to hear where this would have helped and where it would have got in your way.
//Adrian
If we transfer this to modern "agentic" software engineering, it's similar to saying every stage needs its own agent and the context of the previous one shouldn't leak into the next one. which works better yes and one can optimize each step separately too.